Last update, July, 2015
-
-
SPPAS is a scientific computer software package written and maintained by Brigitte Bigi of the Laboratoire Parole et Langage, in Aix-en-Provence, France.
Operating systems:
-
GNU Public License, version 3
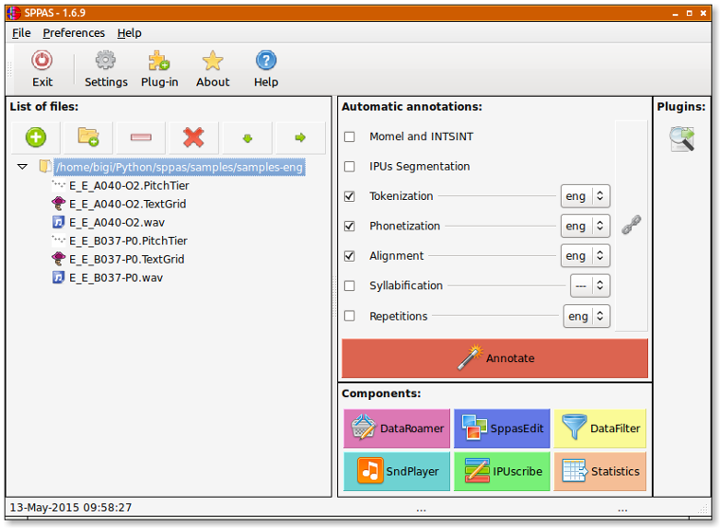
All the automatic annotations are based on language independent approaches
-
This means:
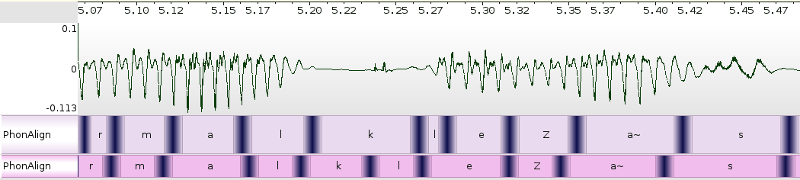
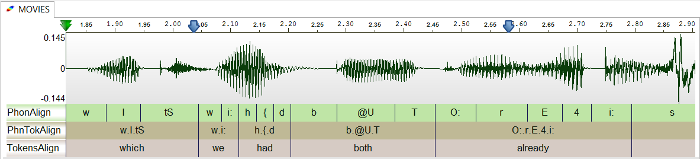
The process of taking the text transcription of an audio speech segment and determining where in time particular phonemes occur in the speech segment
-
-
-
Each automatic annotation generates a file and...
Open such file(s) in the SppasEdit component, or Praat, or Elan, ...
-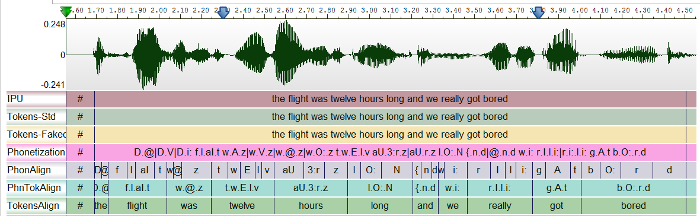
Save/Export any file into any format (XRA, TextGrid, EAF, CSV) with one of the 'Export' buttons
You are now ready to test SPPAS with the proposed set of samples...
... and do not forget to read the documentation: it contains most of the answers to your questions!
-![]()