This chapter is not a description on how each automatic annotation is implemented and how it's working: the references are available for that specific purpose!
Instead, this chapter describes how each automatic annotation can be used in SPPAS, i.e. what is the goal of the annotation, what are the requirements, what kind of resources are used, and what is the expected result. Each automatic annotation is then illustrated as a workflow schema, where:
At the end of each automatic annotation process, SPPAS produces a Procedure Outcome Report that aims to be read!
Among others, SPPAS is able to produce automatically annotations from a recorded speech sound and its orthographic transcription. Let us first introduce what is the exaclty meaning of "recorded speech" and "orthographic transcription".
When using the Graphical User Interface, the file format for input and output can be fixed in the Settings and is applied to all annotations, and file names of each annotation is already fixed and can't be changed. When using the Command-Line interface, or when using scripts, each annotation can be configured independently (file format and file names). In all cases, the name of the tiers are fixed and can't be changed!
First of all:
Only
wav,aiffandauaudio files and only as mono are supported by SPPAS.
SPPAS verifies if the wav file is 16 bits and 16000 Hz sample rate. Otherwise it automatically converts to this configuration. For very long files, this may take time. So, the following are possible:
Secondly, a relatively good recording quality is expected. Providing a guideline or recommendation for that is impossible, because it depends: "IPU segmentation" requires a better quality compared to what is expected by "Alignment", and for that latter, it depends on the language.
Only UTF-8 encoding is supported by SPPAS.
Clearly, there are different ways to pronounce the same utterance. Different speakers have different accents and tend to speak at different rates. There are commonly two types of Speech Corpora. First is related to “Read Speech” which includes book excerpts, broadcast news, lists of words, sequences of numbers. Second is often named as “Spontaneous Speech” which includes dialogs - between two or more people (includes meetings), narratives - a person telling a story, map- tasks - one person explains a route on a map to another, appointment-tasks - two people try to find a common meeting time based on individual schedules. One of the characteristics of Spontaneous Speech is an important gap between a word’s phonological form and its phonetic realizations. Specific realization due to elision or reduction processes are frequent in spontaneous data. It also presents other types of phenomena such as non-standard elisions, substitutions or addition of phonemes which intervene in the automatic phonetization and alignment tasks.
Consequently, when a speech corpus is transcribed into a written text, the transcriber is immediately confronted with the following question: how to reflect the orality of the corpus? Transcription conventions are then designed to provide rules for writing speech corpora. These conventions establish phenomena to transcribe and also how to annotate them.
In that sense, the orthographic transcription must be a representation of what is “perceived” in the signal. Consequently, it must includes:
In speech (particularly in spontaneous speech), many phonetic variations occur. Some of these phonologically known variants are predictable and can be included in the pronunciation dictionary but many others are still unpredictable (especially invented words, regional words or words borrowed from another language).
SPPAS is the only automatic annotation software that deals with Enriched Orthographic Transcriptions.
The transcription must use the following convention:
SPPAS also allows to include in the transcription:
The result is what we call an enriched orthographic construction, from which two derived transcriptions are generated automatically: the standard transcription (the list of orthographic tokens) and a specific transcription from which the phonetic tokens are obtained to be used by the grapheme-phoneme converter that is named faked transcription.
This is + hum... an enrich(ed) transcription {loud} number 1!
The derived transcriptions are:
The "IPUs segmentation" automatic annotation can perform 3 actions:
The IPUs Segmentation annotation performs a silence detection from a recorded file. This segmentation provides an annotated file with one tier named "IPU". The silence intervals are labelled with the "#" symbol, as speech intervals are labelled with "ipu_" followed by the IPU number.
The following parameters must be fixed:
Minimum volume value (in seconds):
If this value is set to zero, the minimum volume is automatically adjusted for each sound file. Try with it first, then if the automatic value is not correct, fix it manually. The Procedure Outcome Report indicates the value the system choose. The SndRoamer component can also be of great help: it indicates min, max and mean volume values of the sound.
Minimum silence duration (in seconds): By default, this is fixed to 0.2 sec., an appropriate value for French. This value should be at least 0.25 sec. for English.
Minimum speech duration (in seconds): By default, this value is fixed to 0.3 sec. The most relevent value depends on the speech style: for isolated sentences, probably 0.5 sec should be better, but it should be about 0.1 sec for spontaneous speech.
Speech boundary shift (in seconds): a duration which is systematically added to speech boundaries, to enlarge the speech interval.
The procedure outcome report indicates the values (volume, minimum durations) that was used by the system for each sound file given as input. It also mentions the name of the output file (the resulting file). The file format can be fixed in the Settings of SPPAS (xra, TextGrid, eaf, ...).

The annotated file can be checked manually (preferably in Praat than Elan nor Anvil). If such values was not correct, then, delete the annotated file that was previously created, change the default values and re-annotate.

Notice that the speech segments can be transcribed using the "IPUScribe" component.
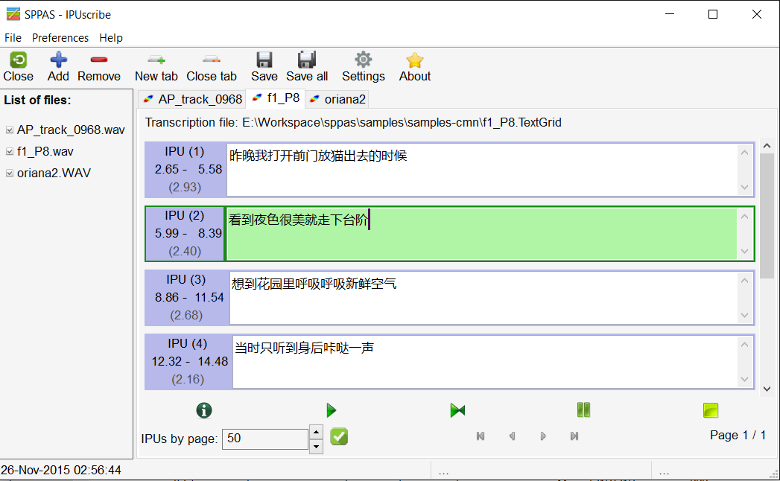
Inter-Pausal Units segmentation can also consist in aligning macro-units of a document with the corresponding sound.
SPPAS identifies silent pauses in the signal and attempts to align them with the inter-pausal units proposed in the transcription file, under the assumption that each such unit is separated by a silent pause. This algorithm is language-independent: it can work on any language.
In the transcription file, silent pauses must be indicated using both solutions, which can be combined:
A recorded speech file must strictly correspond to a transcription, except for the extension expected as .txt for this latter. The segmentation provides an annotated file with one tier named "IPU". The silence intervals are labelled with the "#" symbol, as speech intervals are labelled with "ipu_" followed by the IPU number then the corresponding transcription.
The same parameters than those indicated in the previous section must be fixed.
Important:
This segmentation was tested on documents no longer than one paragraph
(about 1 minute speech). 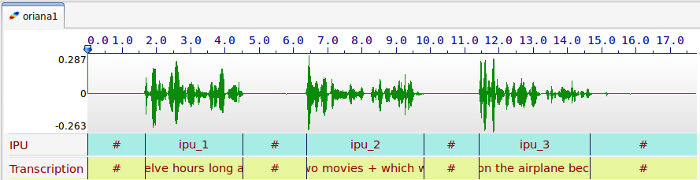
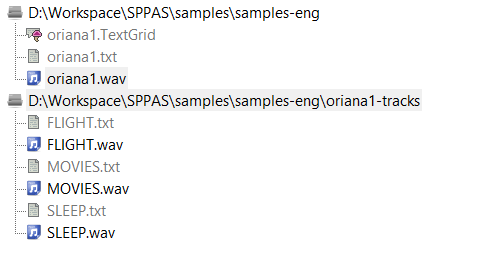
IPU segmentation can split the sound into multiple files (one per IPU), and it creates a text file for each of the tracks. The output file names are "track_0001", "track_0002", etc.
Optionally, if the input annotated file contains a tier named exactly "Name", then the content of this tier will be used to fix output file names.
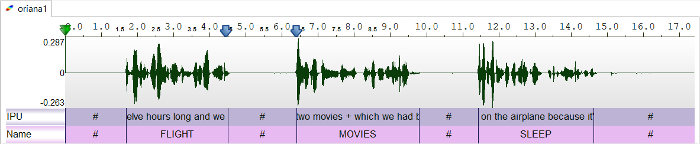
In the example above, the automatic process will create 6 files: FLIGTH.wav, FLIGHT.txt, MOVIES.wav, MOVIES.txt, SLEEP.wav and SLEEP.txt. It is up to the user to perform another IPU segmentation of these files to get another file format than txt (xra, TextGrid, ...) thanks to the previous section "Silence/Speech segmentation time-aligned with a transcription".
Tokenization is also known as "Text Normalization" the process of segmenting a text into tokens. In principle, any system that deals with unrestricted text need the text to be normalized. Texts contain a variety of "non-standard" token types such as digit sequences, words, acronyms and letter sequences in all capitals, mixed case words, abbreviations, roman numerals, URL's and e-mail addresses... Normalizing or rewriting such texts using ordinary words is then an important issue. The main steps of the text normalization proposed in SPPAS are:
For more details, see the following reference:
Brigitte Bigi (2011). A Multilingual Text Normalization Approach. 2nd Less-Resourced Languages workshop, 5th Language Technology Conference, Poznàn (Poland).
The SPPAS Tokenization system takes as input a file including a tier with the orthographic transcription. The name of this tier must contains one of the following strings:
The first tier that matches is used (case insensitive search).
By default, it produces a file including only one tier with the tokens. To get both transcription tiers faked and standard, check such option!
Read the "Introduction" of this chapter to understand the difference between "standard" and "faked" transcriptions.
Phonetization, also called grapheme-phoneme conversion, is the process of representing sounds with phonetic signs.
SPPAS implements a dictionary based-solution which consists in storing a maximum of phonological knowledge in a lexicon. In this sense, this approach is language-independent. SPPAS phonetization process is the equivalent of a sequence of dictionary look-ups.
The SPPAS phonetization takes as input an orthographic transcription previously normalized (by the Tokenization automatic system or manually). The name of this tier must contains one of the following strings:
The first tier that matches is used (case insensitive search).
The system produces a phonetic transcription.
Actually, some words can correspond to several entries in the dictionary with various pronunciations, all these variants are stored in the phonetization result. By convention, spaces separate words, dots separate phones and pipes separate phonetic variants of a word. For example, the transcription utterance:
the flight was twelve hours longdh.ax|dh.ah|dh.iy f.l.ay.t w.aa.z|w.ah.z|w.ax.z|w.ao.z t.w.eh.l.v aw.er.z|aw.r.z l.ao.ngMany of the other systems assume that all words of the speech transcription are mentioned in the pronunciation dictionary. On the contrary, SPPAS includes a language-independent algorithm which is able to phonetize unknown words of any language as long as a dictionary is available! If such case occurs during the phonetization process, a WARNING mentions it in the Procedure Outcome Report.
For details, see the following reference:
Brigitte Bigi (2013). A phonetization approach for the forced-alignment task, 3rd Less-Resourced Languages workshop, 6th Language & Technology Conference, Poznan (Poland).
Since the phonetization is only based on the use of a pronunciation dictionary, the quality of such a phonetization only depends on this resource. If a pronunciation is not as expected, it is up to the user to change it in the dictionary. All dictionaries are located in the sub-directory "dict" of the "resources" directory.
SPPAS uses the same dictionary-format as proposed in VoxForge, i.e. the HTK ASCII format. Here is a peace of the eng.dict file:
THE [THE] D @
THE(2) [THE] D V
THE(3) [THE] D i:
THEA [THEA] T i: @
THEALL [THEALL] T i: l
THEANO [THEANO] T i: n @U
THEATER [THEATER] T i: @ 4 3:r
THEATER'S [THEATER'S] T i: @ 4 3:r zThe first column indicates the word, followed by the variant number (except for the first one). The second column indicated the word between brackets. The last columns are the succession of phones, separated by a whitespace.
Alignment, also called phonetic segmentation, is the process of aligning speech with its corresponding transcription at the phone level. The alignment problem consists in a time-matching between a given speech unit along with a phonetic representation of the unit.
SPPAS is based on the Julius Speech Recognition Engine (SRE). Speech Alignment also requires an Acoustic Model in order to align speech. An acoustic model is a file that contains statistical representations of each of the distinct sounds of one language. Each phoneme is represented by one of these statistical representations. SPPAS is working with HTK-ASCII acoustic models, trained from 16 bits, 16000 Hz wav files.
Speech segmentation was evaluated for French: in average, automatic speech segmentation is 95% of times within 40ms compared to the manual segmentation (tested on read speech and on conversational speech). Details about these results are available in the slides of the following reference:
Brigitte Bigi (2014). Automatic Speech Segmentation of French: Corpus Adaptation. 2nd Asian Pacific Corpus Linguistics Conference, p. 32, Hong Kong.
The SPPAS aligner takes as input the phonetization and optionally the tokenization. The name of the phonetization tier must contains the string "phon". The first tier that matches is used (case insensitive search).
The annotation provides one annotated file with 3 tiers:
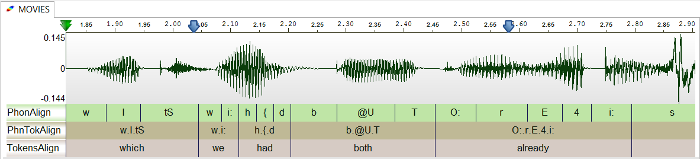
The following options are available to configure alignment:
The syllabification of phonemes is performed with a rule-based system from time-aligned phonemes. This phoneme-to-syllable segmentation system is based on 2 main principles:
These two principles focus the problem of the task of finding a syllabic boundary between two vowels. As in state-of-the-art systems, phonemes were grouped into classes and rules established to deal with these classes. We defined general rules followed by a small number of exceptions. Consequently, the identification of relevant classes is important for such a system.
We propose the following classes, for both French and Italian set of rules:
The rules we propose follow usual phonological statements for most of the corpus. A configuration file indicates phonemes, classes and rules. This file can be edited and modified to adapt the syllabification.
For more details, see the following reference:
B. Bigi, C. Meunier, I. Nesterenko, R. Bertrand (2010). Automatic detection of syllable boundaries in spontaneous speech. Language Resource and Evaluation Conference, pp 3285-3292, La Valetta, Malte.

The Syllabification annotation takes as input one file with (at least) one tier containing the time-aligned phonemes. The annotation provides one annotated file with 3 tiers (Syllables, Classes and Structures).
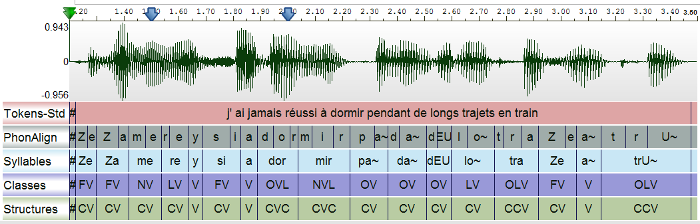
If the syllabification is not as expected, you can change the set of rules. The configuration file is located in the sub-directory "syll" of the "resources" directory.
The syllable configuration file is a simple ASCII text file that any user can change as needed. At first, the list of phonemes and the class symbol associated with each of the phonemes are described as, for example:
PHONCLASS e VPHONCLASS p OThe couples phoneme/class are made of 3 columns: the first column is the key-word PHONCLASS, the second column is the phoneme symbol, the third column is the class symbol.The constraints on this definition are:
The second part of the configuration file contains the rules. The first column is a keyword, the second column describes the classes between two vowels and the third column is the boundary location. The first column can be:
GENRULE,EXCRULE, orOTHRULE.In the third column, a 0 means the boundary is just after the first vowel, 1 means the boundary is one phoneme after the first vowel, etc. Here are some examples, corresponding to the rules described in this paper for spontaneous French:
GENRULE VXV 0GENRULE VXXV 1EXCRULE VFLV 0EXCRULE VOLGV 0Finally, to adapt the rules to specific situations that the rules failed to model, we introduced some phoneme sequences and the boundary definition. Specific rules contain only phonemes or the symbol "ANY" which means any phoneme. It consists of 7 columns: the first one is the key-word OTHRULE, the 5 following columns are a phoneme sequence where the boundary should be applied to the third one by the rules, the last column is the shift to apply to this boundary. In the following example:
OTHRULE ANY ANY p s k -2
This automatic detection focus on word repetitions, which can be an exact repetition (named strict echo) or a repetition with variation (named non-strict echo).
SPPAS implements self-repetitions and other-repetitions detection. The system is based only on lexical criteria. The proposed algorithm is focusing on the detection of the source.
The Graphical User Interface only allows to detect self-repetitions. Use the Command-Line User Interface if you want to get other-repetitions.
For more details, see the following paper:
Brigitte Bigi, Roxane Bertrand, Mathilde Guardiola (2014). Automatic detection of other-repetition occurrences: application to French conversational speech, 9th International conference on Language Resources and Evaluation (LREC), Reykjavik (Iceland).
The automatic annotation takes as input a file with (at least) one tier containing the time-aligned tokens of the speaker (and another file/tier for other-repetitions). The annotation provides one annotated file with 2 tiers (Sources and Repetitions).
This process requires a list of stop-words, and a dictionary with lemmas (the system can process without it, but the result is better with it). Both lexicons are located in the "vocab" sub-directory of the "resources" directory.
Momel is an algorithm for the automatic modelling of fundamental frequency (F0) curves using a technique called assymetric modal quaratic regression.
This technique makes it possible by an appropriate choice of parameters to factor an F0 curve into two components:
The algorithm which we call Asymmetrical Modal Regression comprises the following four stages:
For details, see the following reference:
Daniel Hirst and Robert Espesser (1993). Automatic modelling of fundamental frequency using a quadratic spline function. Travaux de l’Institut de Phonétique d’Aix. vol. 15, pages 71-85.
The SPPAS implementation of Momel requires a file with the F0 values, sampled at 10 ms. Two extensions are supported:
These options can be fixed:
INTSINT assumes that pitch patterns can be adequately described using a limited set of tonal symbols, T,M,B,H,S,L,U,D (standing for : Top, Mid, Bottom, Higher, Same, Lower, Up-stepped, Down-stepped respectively) each one of which characterises a point on the fundamental frequency curve.
The rationale behind the INTSINT system is that the F0 values of pitch targets are programmed in one of two ways : either as absolute tones T, M, B which are assumed to refer to the speaker’s overall pitch range (within the current Intonation Unit), or as relative tones H, S, L, U, D assumed to refer only to the value of the preceding target point.
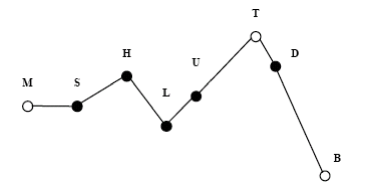
The rationale behind the INTSINT system is that the F0 values of pitch targets are programmed in one of two ways : either as absolute tones T, M, B which are assumed to refer to the speaker’s overall pitch range (within the current Intonation Unit), or as relative tones H, S, L, U, D assumed to refer only to the value of the preceding target point.
A distinction is made between non-iterative H, S, L and iterative U, D relative tones since in a number of descriptions it appears that iterative raising or lowering uses a smaller F0 interval than non-iterative raising or lowering. It is further assumed that the tone S has no iterative equivalent since there would be no means of deciding where intermediate tones are located.
D.-J. Hirst (2011). The analysis by synthesis of speech melody: from data to models, Journal of Speech Sciences, vol. 1(1), pages 55-83.
Brigitte Bigi © 2011-2015