
SPPAS implements an Application Programming Interface (API), named annotationdata, to deal with annotated files.
annotationdata API is a free and open source Python library to access and search data from annotated data. It can convert file formats like Elan’s EAF, Praat's TextGrid and others into a Transcription object and convert this object into anyone of these formats. This object allows unified access to linguistic data from a wide range sources.
In this chapter, we are going to create Python scripts with the SPPAS Application Programming Interface annotationdata and then run them. This chapter includes examples and some exercises to practice. Solutions of the exercises are included in the package sub-directory documentation, then solutions.
annotationdata is based on the Programming Language Python, version 2.7. This chapter firstly introduces basic programming concepts, then it will gradually introduce how to write scripts with Python. Those who are familiar with programming in Python can directly go to the last section related to the description of the annotationdata API and how to use it in Python scripts.
In this chapter, it is assumed that Python 2.7 is already installed and configured. It is also assumed that the Python IDLE is ready-to-use. For more details about Python, see:
The Python Website: http://www.python.org
This section is partially made of selected parts of the Python website and wikipedia.
Programming is the process of writing instructions for computers to produce software for users. More than anything, it is a creative and problem-solving activity. Any problem can be solved in a large number of ways.
An algorithm is the step-by-step solution to a certain problem: algorithms are lists of instructions which are followed step by step, from top to bottom and from left to right. To practice writing programs in a programming language, it is required first to think of a the problem and consider the logical solution before writing it out.
Writing a program is done so using a programming language. Thankfully even though some languages are vastly different than others, most share a lot of common ground, so that once anyone knows his/her first language, other languages are much easier to pick up.
Any program is made of statements. A statement is more casually (and commonly) known as a line of code is the smallest standalone element which expresses some action to be carried out while executing the program. It can be one of: comment, assignment, conditions, iterations, etc. Most languages have a fixed set of statements defined by the language.s
Lines of code are grouped in blocks. Blocks are delimited by brackets, braces or by the indentation (depending on the programming language).
The prompt indicates the system is ready to receive input. Most of times, it is represented by '>'. In the following, the prompt is not mentioned.
Comments are not required by the program to work. But comments are necessary! It is commonly admitted that about 25% to 30% of lines of a program must be comments.
# this is a comment in python, bash and others.
# I can write what I want after the # symbol :-)~A variable in any programming language is a named piece of computer memory, containing some information inside. When declaring a variable, it is usually also stated what kind of data it should carry. Assignment is setting a variable to a value. Dynamically typed languages, such as Python, allow automatic conversions between types according to defined rules.
Python variables do not have to be explicitly declared: the declaration happens automatically when a value is assigned to a variable. In most languages, the equal sign (=) is used to assign values to variables.
a = 1
b = 1.0
c = 'c'
hello = 'Hello world!'
vrai = TrueIn the previous example, a, b, c, hello and vrai are variables, a = 1 is a declaration with a typed-statement.
Here is a list of some fundamental data types, and their characteristics:
True or FalseNotice that the number 0 represents the boolean value False.
Assignments are performed with operators. Python Assignment Operators are:
a = 10 # simple assignment operator
a += 10 # add and assignment operator
a -= 10
a *= 10
a /= 10Notice that a Character is a single letter, number, punctuation or other value; and a String is a collection of these character values, often manipulated as if it were a single value.
Complex data types are often used, for example: arrays, lists, tree, hash-tables, etc. For example, with Python:
lst = ['a', 'bb', 'ccc', 'dddd', 'eeeee' ]
sublst = lst[1:2]Python Arithmetic Operators:
a = 10
b = 20
a + b # Addition
a - b # Subtraction
a * b # Multiplication
a / b # Division
float(a) / float(b) # try it! and compare with the previous oneDecision making structures require that the programmer specify one or more conditions to be evaluated or tested by the program. The condition statement is a simple control that tests whether a statement is true or false. The condition can include a variable, or be a variable. If the condition is true, then an action occurs. If the condition is false, nothing is done.
Conditions are performed with the help of comparison operators, as equal, less than, greater than, etc.
In the following, we give example of conditions/comparisons in Python.
var = 100
if var == 100: print "Value of expression is 100"Python programming language assumes any non-zero and non-null values as True, and if it is either zero or null, then it is assumed as False value.
if a == b:
print 'equals'
elif a > b:
print 'a greater than b'
else:
print 'b greater than a'Python Comparison Operators:
a == b # check if equals
a != b # check if different
a > b # check if a is greater than b
a >= b # check if a is greater or equal to b
a < b
a <= bOther Python Operators:
and Called Logical AND operator. If both the operands are true then the condition becomes true.or Called Logical OR Operator. If any of the two operands are non zero then the condition becomes true.not Called Logical NOT Operator. Use to reverses the logical state of its operand. If a condition is true then Logical NOT operator will make false.in Evaluates to true if it finds a variable in the specified sequence and false otherwise.A "loop" is a process in which a loop is initiated until a condition has been met.
A while loop statement repeatedly executes a target statement as long as a given condition is true.
The for loop has the ability to iterate over the items of any sequence, such as a list or a string. The following Python program prints items of a list on the screen:
l = ['fruits', 'viande', 'poisson', 'oeufs']
for item in l:
print itemWe are going to create a very simple Python script and then run it. First of all, create a new folder (on your Desktop for example); you can name it "pythonscripts" for example.
Execute the python IDLE (available in the Application-Menu of your operating system).
Then, create a new empty file:
Copy the following code in this newly created file.
1 | |
Then, save the file in the "pythonscripts" folder. By convention, Python source files end with a .py extension, so I suggest the name 01_helloworld.py.
Notice that main (in the code above) is a function.
A function does something. This particular function prints, or outputs to the screen, the text, or string, between apostrophes or quotation marks. We've decided to call this function main: the name main is just a convention. We could have called it anything.
To execute the program, you can do one of:
The expected output is as follow:
A better practice while writing scripts is to describe by who, what and why this script was done. I suggest to create a skeleton for your future scripts, it is useful each time a new script will have to be written.
Here is an example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
This ready-to-use script is available in the SPPAS package, its name is skeleton.py.
In the example above, the main function is documented: documentation is the text between """. In this chapter, all these "docstrings" follow a convention, named "The Epytext Markup Language". Epytext is a simple lightweight markup language that lets you add formatting and structure to docstrings. The software Epydoc uses that formatting and structure to produce nicely formatted API documentation. For details, see:
Epydoc web site: http://epydoc.sourceforge.net/manual-epytext.html
Now, we'll play with functions! So, create a copy of the file skeleton.py, and add the following function print_vowels(). This function declare a list named vowels. Each item of the list is a string representing a vowel in French encoded in SAMPA (at the phonetic level). Of course, such list can be overridden with any other set of phonemes. Then, the function print each item of the list, by means of a loop.
21 22 23 24 25 | |
The main() function must be changed: instead of printing 'Hello World!', it will call the newly created function print_vowels().
31 32 33 | |
Then, save the file in the "pythonscripts" folder and execute the program.
Practice: Add a function to print plosives and call it in the main function (solution: 02_functions.py).
One can also create a function to print glides, another one to print affricates, and so on. Hum... this sounds a little bit fastidious! Lets update, or refactor, our printing function to make it more generic.
There are times when we need to do something different with only slight variation each time. Rather than writing the same code with only minor differences over and over, we group the code together and use a mechanism to allow slight variations each time we use it. A function is a smaller program with a specific job. In most languages they can be "passed" data, called parameters, which allow us to change the values they deal with.
Notice that the number of parameters of a function is not limited!
In the example, we can replace the print_vowels() function and the print_plosives() function by a single function print_list(mylist) where mylist can be any list containing strings or characters. If the list contains other typed-variables (as int or float), they must be converted to string to be printed out.
21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Languages usually have a way to return information from a function, and this is called the return data. This is done with the return key-word. The function stops at this stage, even if some code is following in the block.
In the following example, the function would return a boolean value (True if the given string has no character).
21 22 23 | |
Practice: Add this funtion in a new script and try to print various lists (solution: 03_functions.py)
Now, we'll try to get data from a file. Create a new empty file with the following lines (and add as many lines as you want), then, save it with the name "phonemes.csv" (by using UTF-8 encoding):
occlusives ; b ; b
occlusives ; d ; d
fricatives ; f ; f
liquids ; l ; l
nasals ; m ; m
nasals ; n ; n
occlusives ; p ; p
glides ; w ; w
vowels ; a ; a
vowels ; e ; e The following statements are typical statements used to read the content of a file. The first parameter of the function open is the file name, including the path (relative or absolute); and the second argument is the opening mode ('r' is the default value, used for reading).
21 22 23 24 25 26 | |
See the file 04_reading_simple.py for the whole program and try-it (do not forget to change the file name to your own file!).
Like any program... it exists more than one way to solve the problem. The following is a more generic solution, with the ability to deal with various file encodings, thanks to the codecs library:
21 22 23 24 25 26 27 28 29 30 | |
In the previous code, the codecs.open functions got 3 arguments: the file name, the mode (in that case, 'r' means 'read'), and the encoding. The readlines() function get each line of the file f and store it into a list.
The main function can be as follow:
35 36 37 38 39 40 41 42 43 44 45 46 47 | |
See the file 05_reading_file.py for the whole program, and try-it (do not forget to change the file name to your own file!).
Notice that Python os module provides methods that can help you to perform file-processing operations, such as renaming and deleting files. See Python documentation for details: https://docs.python.org/2/
Writing a file requires to open it in a writing mode:
A file can be opened in an encoding and saved in another one. This could be useful to write a script to convert the encoding of a set of files in a given forlder to UTF-8 for example. The following could help to create such a script:
10 11 12 | |
15 16 17 18 19 20 | |
A dictionary is another container type that can store any number of Python objects, including other container types. Dictionaries consist of pairs (called items) of keys and their corresponding values. Each key is separated from its value by a colon (:), the items are separated by commas, and the whole thing is enclosed in curly braces. An empty dictionary without any items is written with just two curly braces, like this: {}. To access dictionary elements, you can use the familiar square brackets along with the key to obtain its value.
The next example is a portion of a program that can be used to convert a list of phonemes from SAMPA to IPA.
To get values from a dictionary, one way is to use directly dict[key], but it is required to test if key is really in dict, otherwise, Python will stop the program and send an error. Alternatively, the get function can be used, as dict.get(key, default=None) where default is the value to return if the key is missing. In the previous example, it is possible to replace sampadict[phone] by sampadict.get(phone, phone). Two other functions are useful while using dictionaries:
Exercise 1: How many vowels are in a list of phonemes? (solution: 06_list.py)
Exercise 2: Write a SAMPA to IPA converter. (solution: 07_dict.py)
Exercise 3: Compare 2 sets of data using NLP techniques (Zipf law, Tf.Idf) (solution: 08_counter.py)
We are now going to write Python scripts with the help of the annotationdata API included in SPPAS. This API is useful to read/write and manipulate files annotated from various annotation tools as Praat or Elan for example.
First of all, it is important to understand the data structure included in the API to be able to use it efficiently. Details can be found in the following publication:
Brigitte Bigi, Tatsuya Watanabe, Laurent Prévot (2014). Representing Multimodal Linguistics Annotated data, Proceedings of the 9th edition of the Language Resources and Evaluation Conference, 26-31 May 2014, Reykjavik, Iceland.
In the Linguistics field, multimodal annotations contain information ranging from general linguistic to domain specific information. Some are annotated with automatic tools, and some are manually annotated. Linguistics annotation, especially when dealing with multiple domains, makes use of different tools within a given project. Many tools and frameworks are available for handling rich media data. The heterogeneity of such annotations has been recognized as a key problem limiting the interoperability and re-usability of NLP tools and linguistic data collections.
In annotation tools, annotated data are mainly represented in the form of "tiers" or "tracks" of annotations. The genericity and flexibility of "tiers" is appropriate to represent any multimodal annotated data because it simply maps the annotations on the timeline. In most tools, tiers are series of intervals defined by:
In Praat, tiers can be represented by a time point and a label (such tiers are named PointTiers and IntervalTiers). Of course, depending on the annotation tool, the internal data representation and the file formats are different. For example, in Elan, unlabelled intervals are not represented nor saved. On the contrary, in Praat, tiers are made of a succession of consecutive intervals (labelled or un-labelled).
The annotationdata API used for data representation is based on the common set of information all tool are currently sharing. This allows to manipulate all data in the same way, regardless of the file type.
The API supports to merge data and annotation from a wide range of heterogeneous data sources for further analysis.
After opening/loading a file, its content is stored in a Transcription object. A Transcription has a name, and a list of Tier objects. This list can be empty. Notice that in a Transcription, two tiers can't have the same name.
A Tier has a name, and a list of Annotation objects. It also contains a set of meta-data and it can be associated to a controlled vocabulary.
A common solution to represent annotation schemes is to put them in a tree. One advantage in representing annotation schemes through those trees, is that the linguists instantly understand how such a tree works and can give a representation of “their” annotation schema. However, each annotation tool is using its own formalism and it is unrealistic to be able to create a generic scheme allowing to map all of them. SPPAS implements another solution that is compatible with trees and/or flat structures (as in Praat). Actually, subdivision relations can be established between tiers. For example, a tier with phonemes is a subdivision reference for syllables, or for tokens, and tokens are a subdivision reference for the orthographic transcription in IPUs. Such subdivisions can be of two categories: alignment or constituency. This data representation allows to keep the Tier representation, which is shared by most of the annotation tools and it allows too to map data on a tree if required: the user can freely create tiers with any names and arrange them in such custom and very easy hierarchy system.
An annotation is made of 2 objects:
Location object,Label object.A Label object is representing the "content" of the annotation. It is a list of Text associated to a score.
A Location is representing where this annotation occurs in the media. Then, a Location is made of a list of Localization which includes the BasePlacement associated with a score. A BasePlacement object is one of: * a TimePoint object; or * a TimeInterval object, which is made of 2 TimePoint objects; or * a TimeDisjoint object which is a list of TimeInterval; or * a FramePoint object; or * a FrameInterval object; or * a FrameDisjoint object.
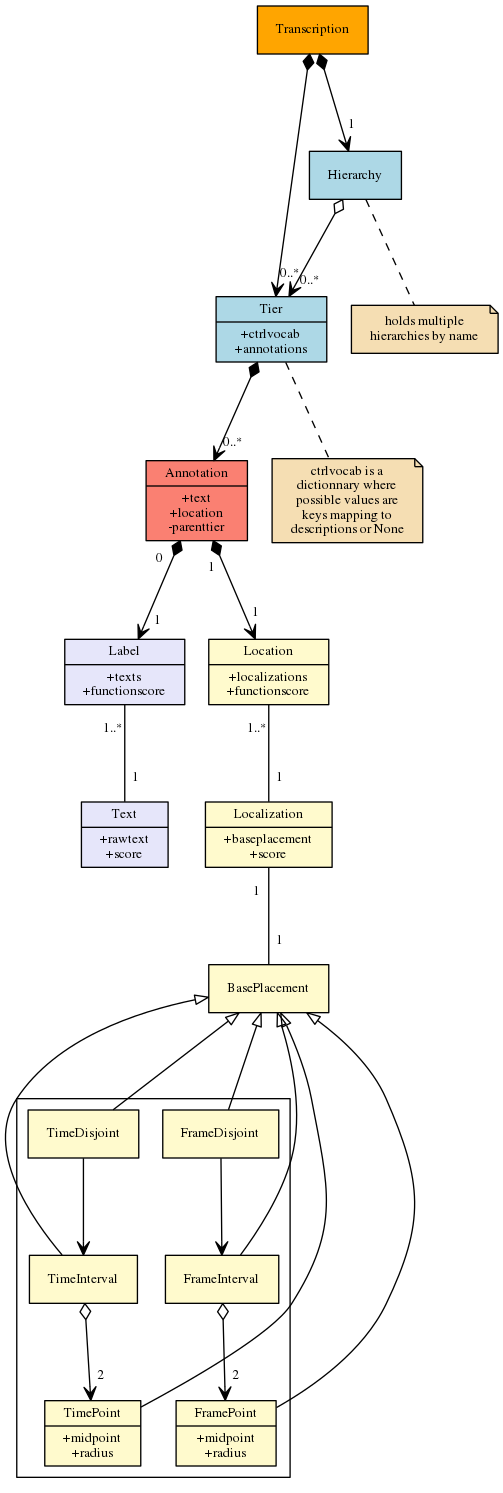
The whole API documentation is available at the following URL: http://sldr.org/000800/preview/manual/module-tree.html
Each annotation holds at least one label, mainly represented in the form of a string, freely written by the annotator or selected from a list of categories, depending on the annotation tool. The "annotationdata" API, aiming at representing any kind of linguistic annotations, allows to assign a score to each label, and allows multiple labels for one annotation. The API also allows to define a controlled vocabulary.
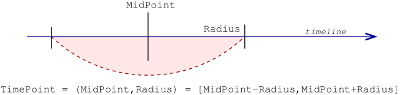
In the annotationdata API, a TimePoint is considered as an imprecise value. It is possible to characterize a point in a space immediately allowing its vagueness by using:
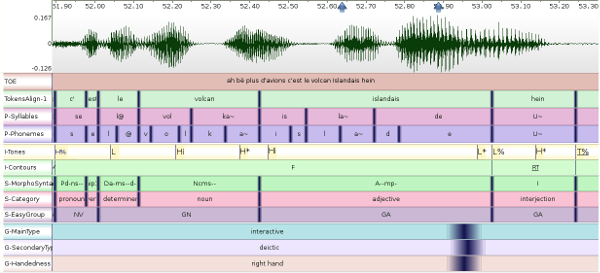
The screenshot below shows an example of multimodal annotated data, imported from 3 different annotation tools. Each TimePoint is represented by a vertical dark-blue line with a gradient color to refer to the radius value (0ms for prosody, 5ms for phonetics, discourse and syntax and 40ms for gestures in this screenshot).
If it is not already done, create a new folder (on your Desktop for example); you can name it "pythonscripts" for example.
Open a File Explorer window and go to the SPPAS folder location. Then, open the sppas directory then src sub-directory. Copy the annotationdata folder then paste-it into the newly created pythonscripts folder.
Open the python IDLE and create a new empty file. Copy the following code in this newly created file, then save the file in the pythonscripts folder. By convention, Python source files end with a .py extension; I suggest skeleton-sppas.py. It will allow to use the SPPAS API in your script.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
Navigate to the folder containing your script, and open-it with the python IDLE. To execute the file:
It will do... nothing! But now, we are ready to do something with the API!
Open/Read a file of any format (TextGrid, Elan, Transcriber, CSV) and store it into a Transcription object instance, named trs in the following code, is mainly done as:
1 | |
Save/Write a Transcription object instance in a file of any format is mainly done as:
2 | |
These two lines of code loads any annotation file (Elan, Praat, Transcriber...) and writes the data into another file. The format of the file is given by its extension, as for example ".xra" is the SPPAS native format, ".TextGrid" is one of the Praat native format, and so on.
So... only both lines are used to convert a file from one format to another one!
In any script, to get the list of accepted extensions as input, just call "annotationdata.io.extensions_in", and the list of accepted extensions as output is "annotationdata.io.extensions_out".
Currently, accepted input file extensions are:
Possible output file extensions are:
Practice: Write a script to convert a TextGrid file into CSV (solution: 10_read_write.py)
The most useful functions used to manage a Transcription object are:
Append(tier), Pop()Add(tier, index), Remove(index)Find(name, case_sensitive=True)Append() is used to add a tier at the end of the list of tiers of the Transcription object; and Pop() is used to remove the last tier of such list.
Add() and Remove() do the same, except that it does not put/delete the tier at the end of the list but at the given index.
Find() is useful to get a tier of the list from its name.
There are useful "shortcuts" that can be used. For example, trs[0] returns the first tier, len(trs) returns the number of tiers and loops can be written as:
15 16 17 | |
Practice: Write a script to select a set of tiers of a file and save them into a new file (solution: 11_transcription.py).
As it was already said, a tier is made of a name and a list of annotations. To get the name of a tier, or to fix a new name, the easier way is to use tier.GetName().
Test the following code into a script:
15 16 17 18 19 20 | |
The most useful functions used to manage a Tier object are:
Append(annotation), Pop()Add(annotation), Remove(begin, end, overlaps=False)IsDisjoint(), IsInterval(), IsPoint()Find(begin, end, overlaps=True)Near(time, direction)SetRadius(radius)Practice: Write a script to open an annotated file and print information about tiers (solution: 12_tiers_info.py)
Goodies:
the file 12_tiers_info_wx.py proposes a GUI to print information of one file or all files of a directory, and to ask the file/directory name with a dialogue frame, instead of fixing it in the script. This script can be executed simply by double-clicking on it in the File Explorer of your system. Many functions of this script can be cut/pasted in any other script.
The most useful function used to manage an Annotation object are:
IsSilence(), IsLabel()IsPoint(), IsInterval(), IsDisjoint()GetBegin(), SetBegin(time), only if time is a TimeIntervalGetEnd(), SetEnd(time), only if time is a TimeIntervalGetPoint(), SetPoint(time), only if time is a TimePointThe following example shows how to get/set a new label, and to set a new time to an annotation:
1 2 3 4 5 6 7 8 9 | |
If something forbidden is attempted, the object will raise an Exception. This means that the program will stop (except if the program "raises" the exception).
Exercise 1: Write a script to print information about annotations of a tier (solution: 13_tiers_info.py)
Exercise 2: Write a script to estimates the frequency of a specific annotation label in a file/corpus (solution: 14_freq.py)
This section focuses on the problem of searching and retrieving data from annotated corpora.
The filter implementation can only be used together with the Tier() class. The idea is that each Tier() can contain a set of filters, that each reduce the full list of annotations to a subset.
SPPAS filtering system proposes 2 main axis to filter such data:
A set of filters can be created and combined to get the expected result, with the help of the boolean function and the relation function.
To be able to apply filters to a tier, some data must be loaded first. First, you have to create a new Transcription() when loading a file. In the next step, you have to select the tier to apply filters on. Then, if the input file was not XRA, it is widely recommended to fix a radius value depending on the annotation type. Now everything is ready to create filters for these data.
In the following, let Bool and Rel two predicates, a tier T, and a filter f.
Pattern selection is an important part to extract data of a corpus. In this case, each filter consists of search terms for each of the tiers that were loaded from an input file. Thus, the following matching predicates are proposed to select annotations (intervals or points) depending on their label. Notice that P represents the text pattern to find:
pr = Bool(exact=P), means that a label is valid if it strictly corresponds to the expected pattern;pr = Bool(contains=P), means that a label is valid if it contains the expected pattern;pr = Bool(startswith=P), means that a label is valid if itstarts with the expected pattern;pr = Bool(endswith=P), means that a label is valid if it ends with the expected pattern.These predicates are then used while creating a filter on labels. All these matches can be reversed, to represent does not exactly match, does not contain, does not start with or does not end with, as for example:
tier = trs.Find("PhonAlign")
ft = Filter(tier)
f1 = LabelFilter( Bool(exact='a'), ft)
f2 = LabelFilter( ~Bool(iexact='a'), ft)In this example, f1 is a filter used to get all phonemes with the exact label 'a'. On the other side, f2 is a filter that ignores all phonemes matching with 'a' (mentioned by the symbol '~') with a case insensitive comparison (iexact means insensite-exact).
For complex search, a selection based on regular expressions is available for advanced users, as pr = Bool(regexp=R).
A multiple pattern selection can be expressed with the operators | to represent the logical "or" and the operator & to represent the logical "and".
With this notation in hands, it is possible to formulate queries as, for example: Extract words starting by "ch" or "sh", as:
pr = Bool(startswith="ch") | Bool(startswith="sh")Filters on duration can also be created on annotations if Time instance is of type TimeInterval. In the following, v represents the value to be compared with:
pr = Bool(duration_lt=v), means that an annotation of T is valid if its duration is lower than v;pr = Bool(duration_le=v);pr = Bool(duration_gt=v);pr = Bool(duration_ge=v);pr = Bool(duration_e=v);Search can also starts and ends at specific time values in a tier by creating filters with begin_ge and end_le.
The, the user must apply the filter to get filtered data from the filter.
1 2 3 4 5 6 7 8 9 10 | |
Relations between annotations is crucial if we want to extract multimodal data. The aim here is to select intervals of a tier depending on what is represented in another tier.
We implemented the 13 Allen interval relations: before, after, meets, met by, overlaps, overlapped by, starts, started by, finishes, finished by, contains, during and equals. Actually, we implemented the 25 relations proposed in the INDU model. This model is fixing constraints on INtervals (with Allen's relations) and on DUration (duration are equals, one is less/greater than the other).
[List of Allen interval relations]<./etc/screenshots/allen.png>
Below is an example of request: Which syllables stretch across 2 words?
1 2 3 4 5 6 7 8 9 10 11 | |
Exercise 1: Create a script to filter annotated data on their label (solution: 15_annotation_label_filter.py).
Exercise 2: Idem with a filter on duration or time. (solution: 16_annotation_time_filter.py).
Exercise 3: Create a script to get tokens followed by a silence. (solution: 17_annotations_relation_filter1.py).
Exercise 4: Create a script to get tokens preceded by OR followed by a silence. (solution: 17_annotations_relation_filter2.py).
Exercise 5: Create a script to get tokens preceded by AND followed by a silence. (solution: 17_annotations_relation_filter3.py).
Brigitte Bigi © 2011-2015