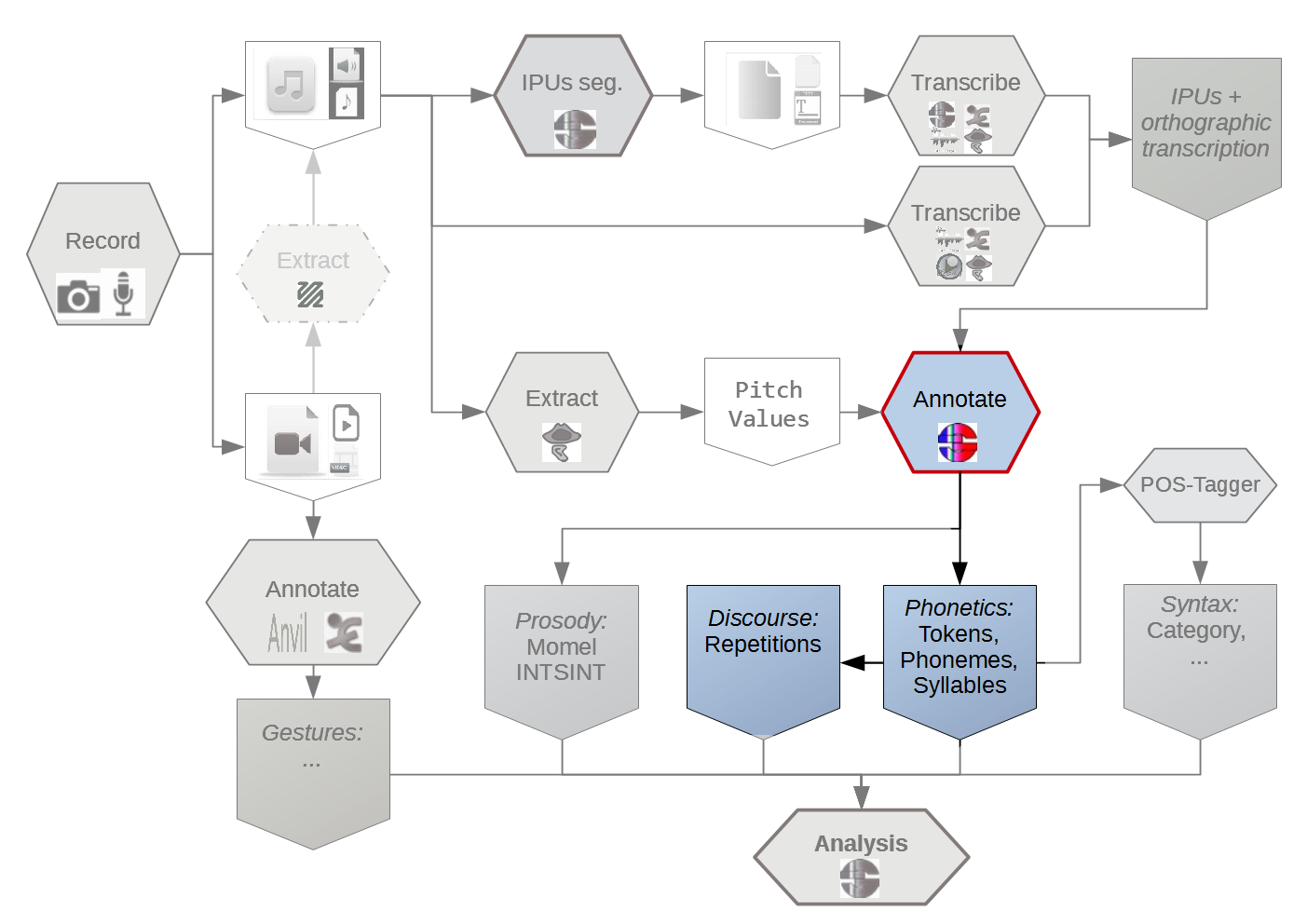
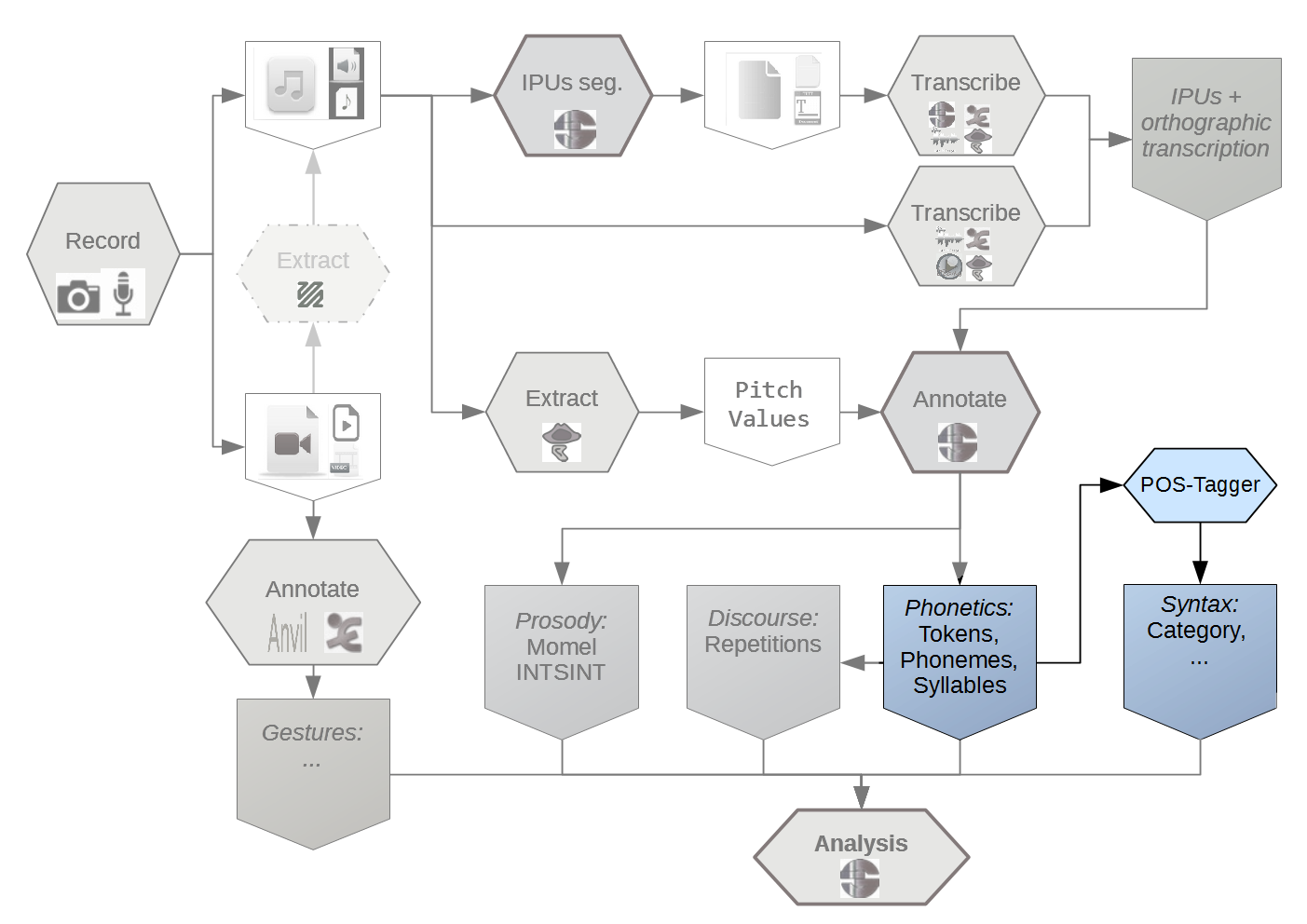
Which annotations (in general)?
In this tutorial, we will report on: 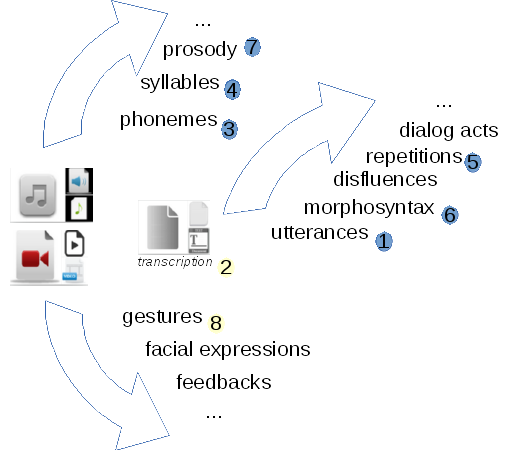
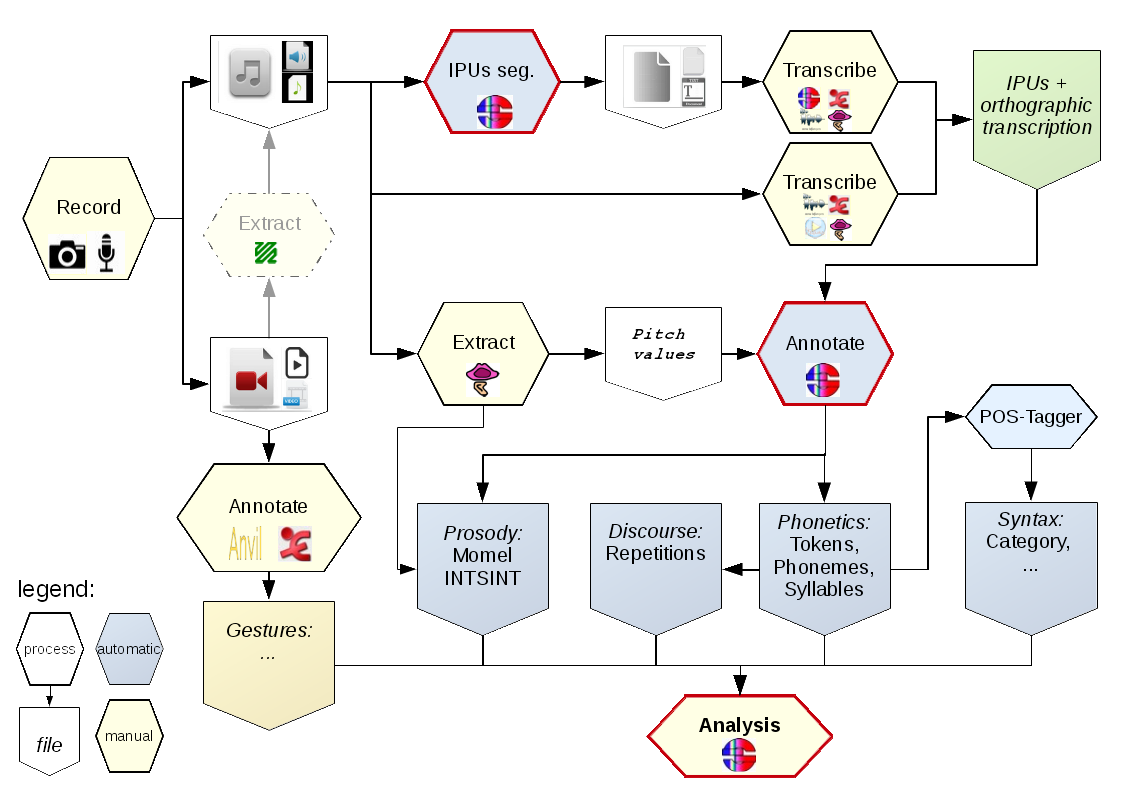
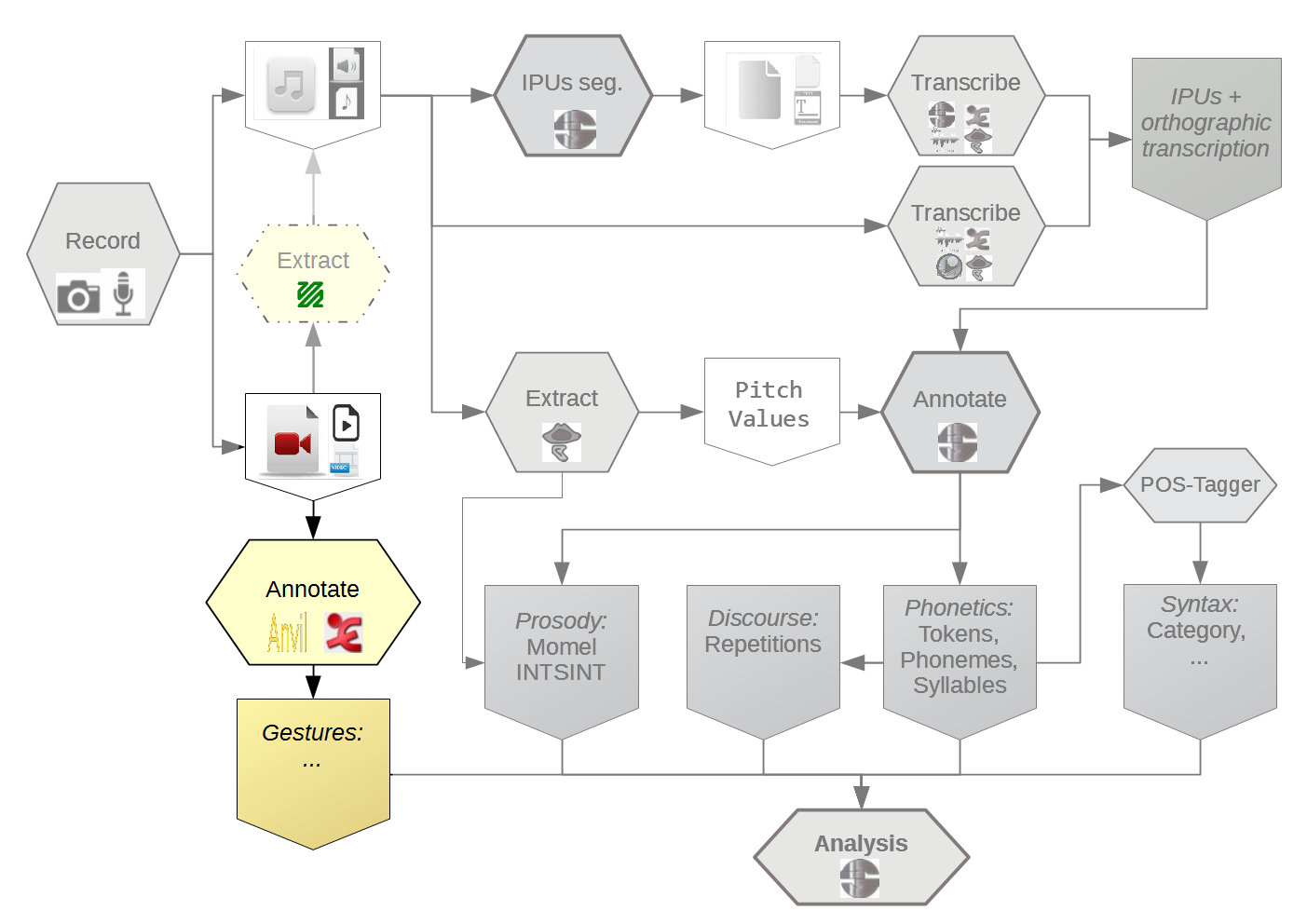
The capture of multimodal corpora requires complex settings such as instrumented lecture and meetings rooms, containing capture devices for each of the modalities that are intended to be recorded, but also, most challengingly, requiring hardware and software for digitizing and synchronizing the acquired signals.
(Popescu-Belis, 2010)

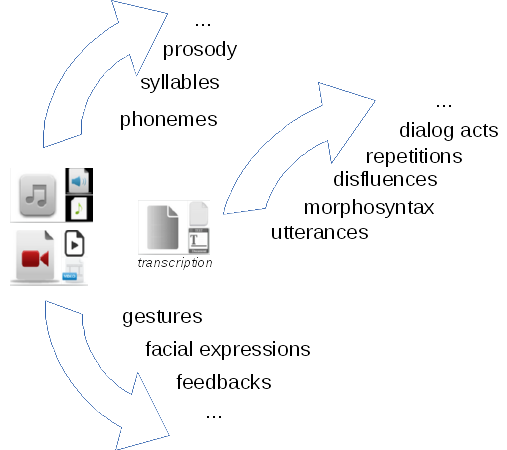
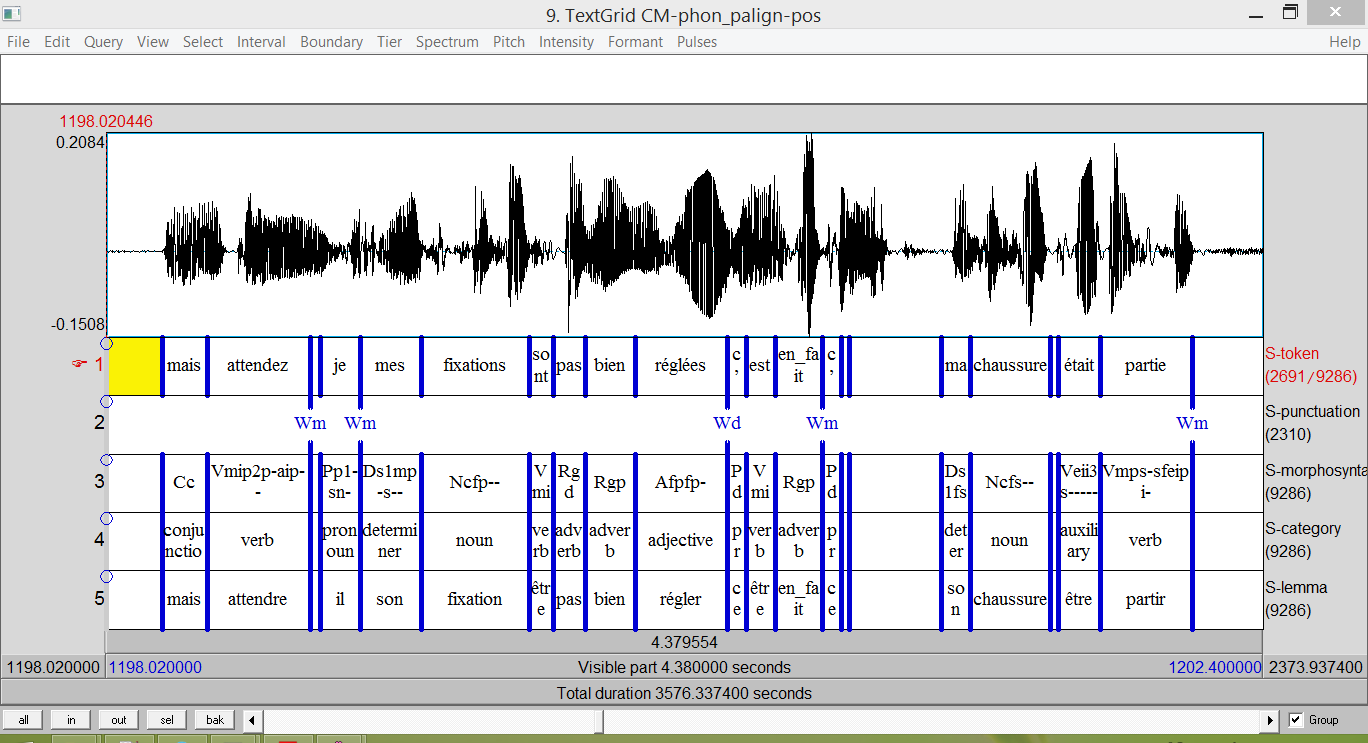
Speech may be annotated for:
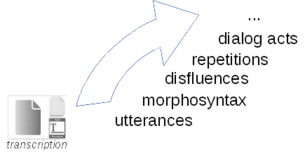


A problem divided into 3 sub-tasks:

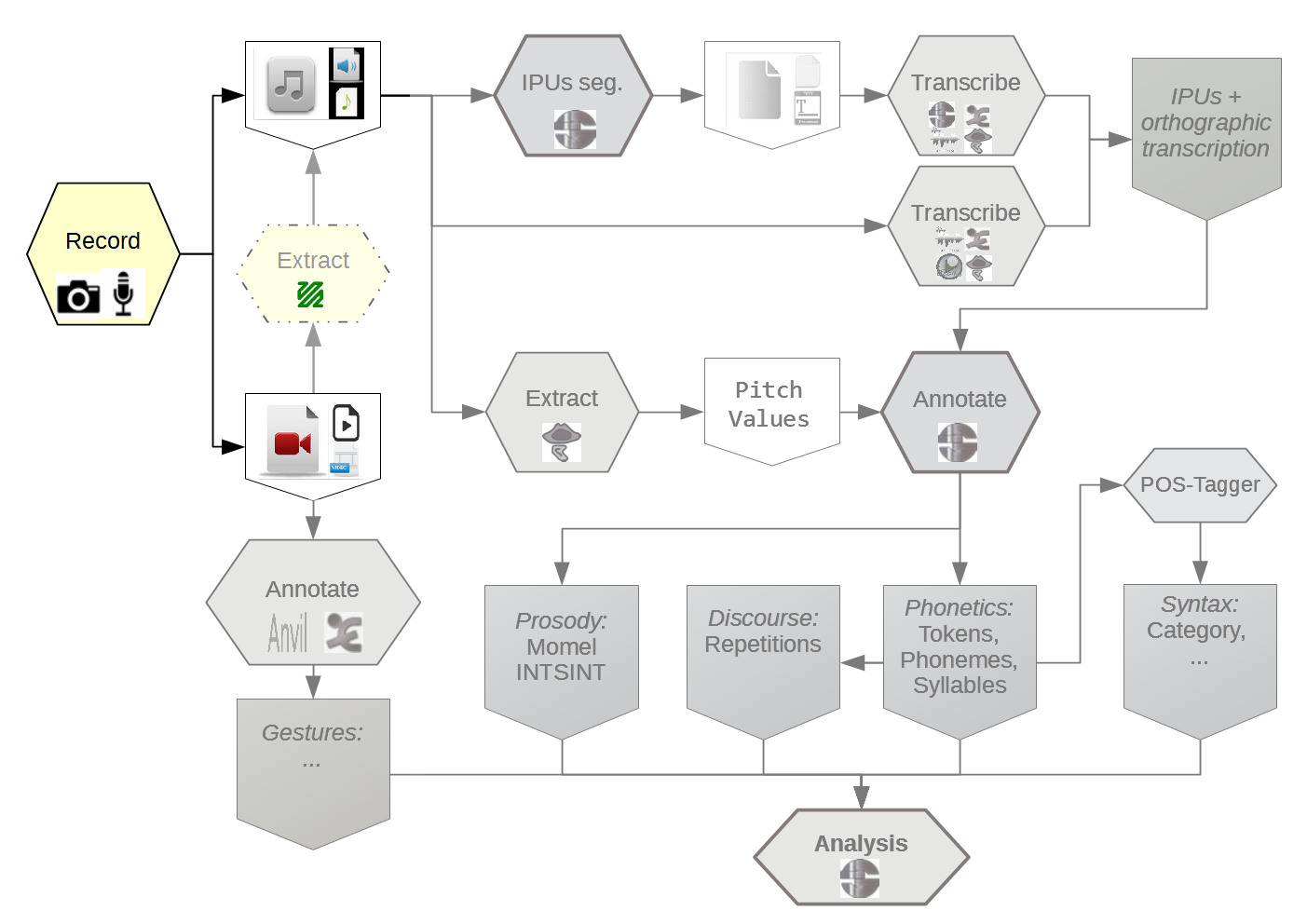
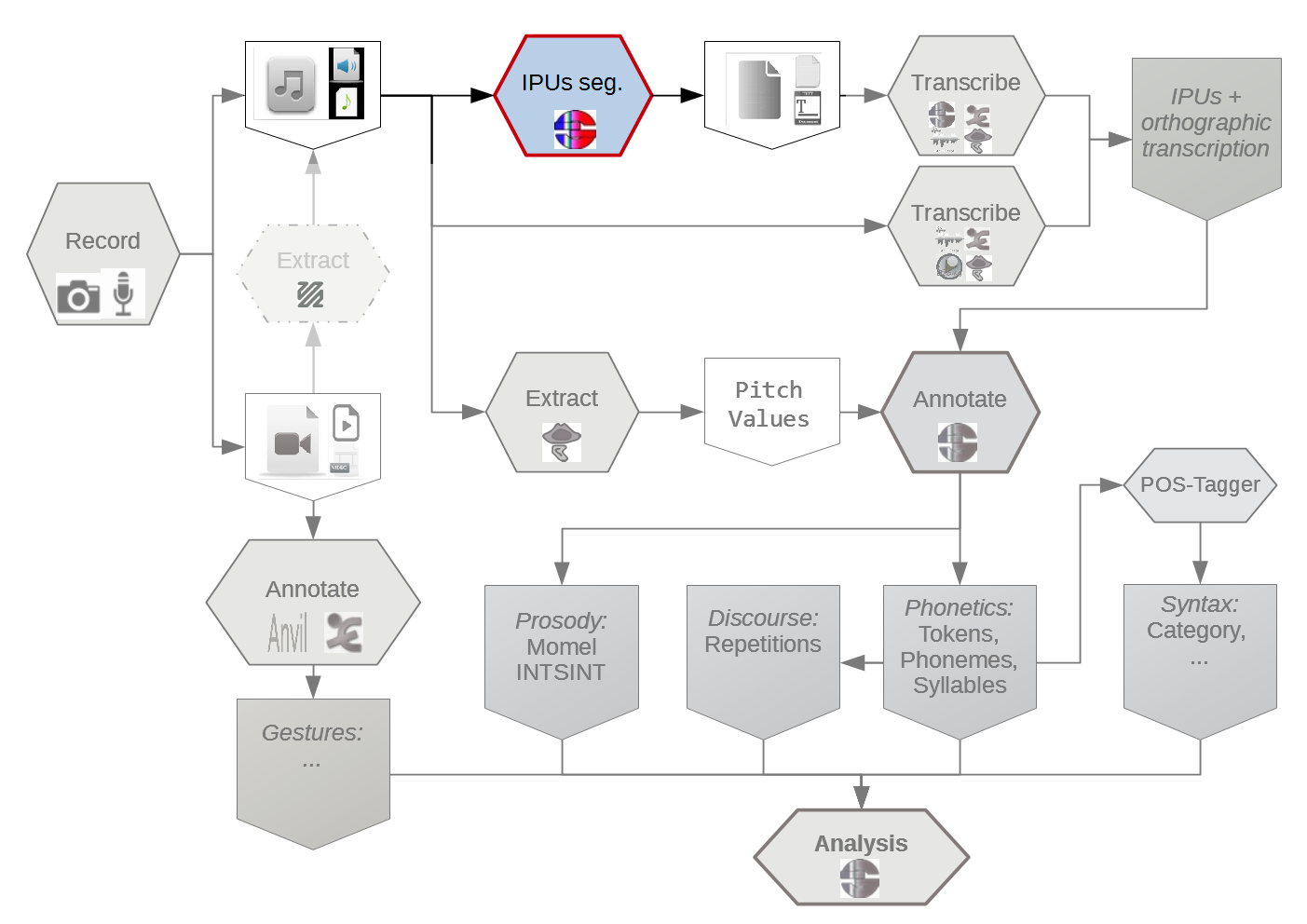
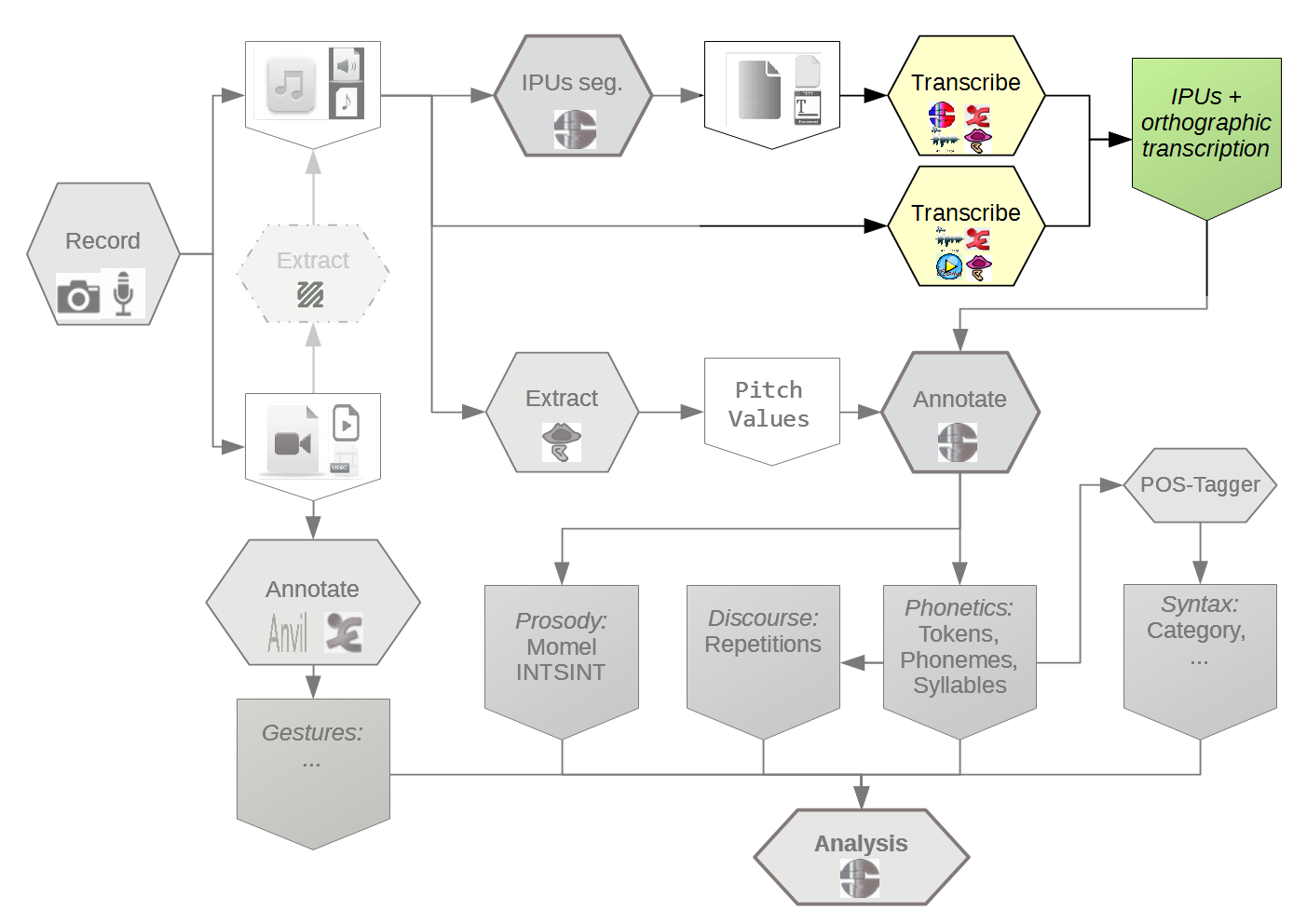
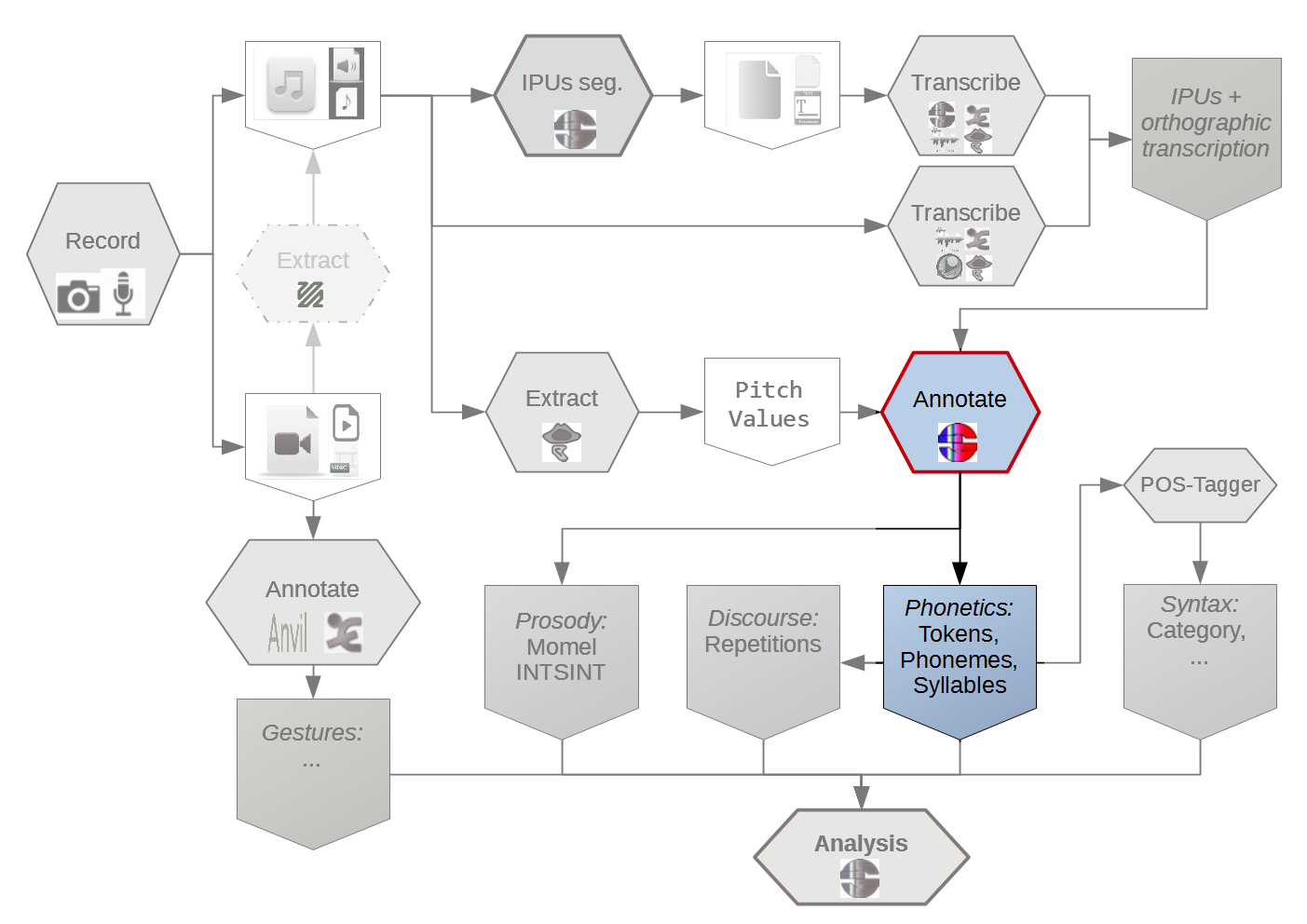
SPPAS implements: (Bigi 2013)

In (Bigi et al. 2012), we compared 3 types of OT:
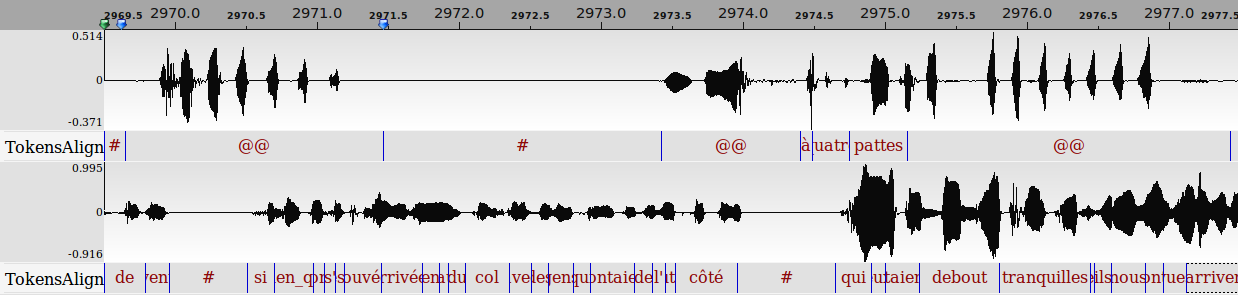
 Evaluations compare a reference phonetized manually to phonetizations obtained with SPPAS
Evaluations compare a reference phonetized manually to phonetizations obtained with SPPAS
Manual alignment has been reported to take between 11 and 30 seconds per phoneme.
(Leung and Zue, 1984)



SPPAS (python+Julius), available for English, French, Italian, Spanish, Catalan, Polish, Japanese, Mandarin Chinese, Taiwanese, Cantonese
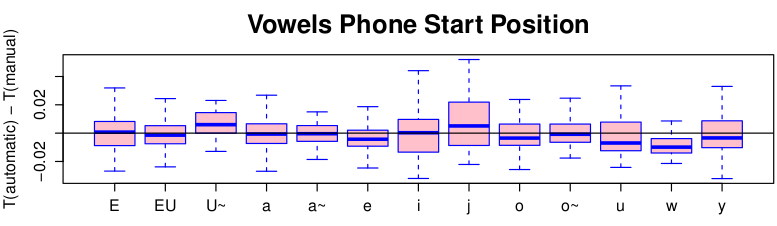

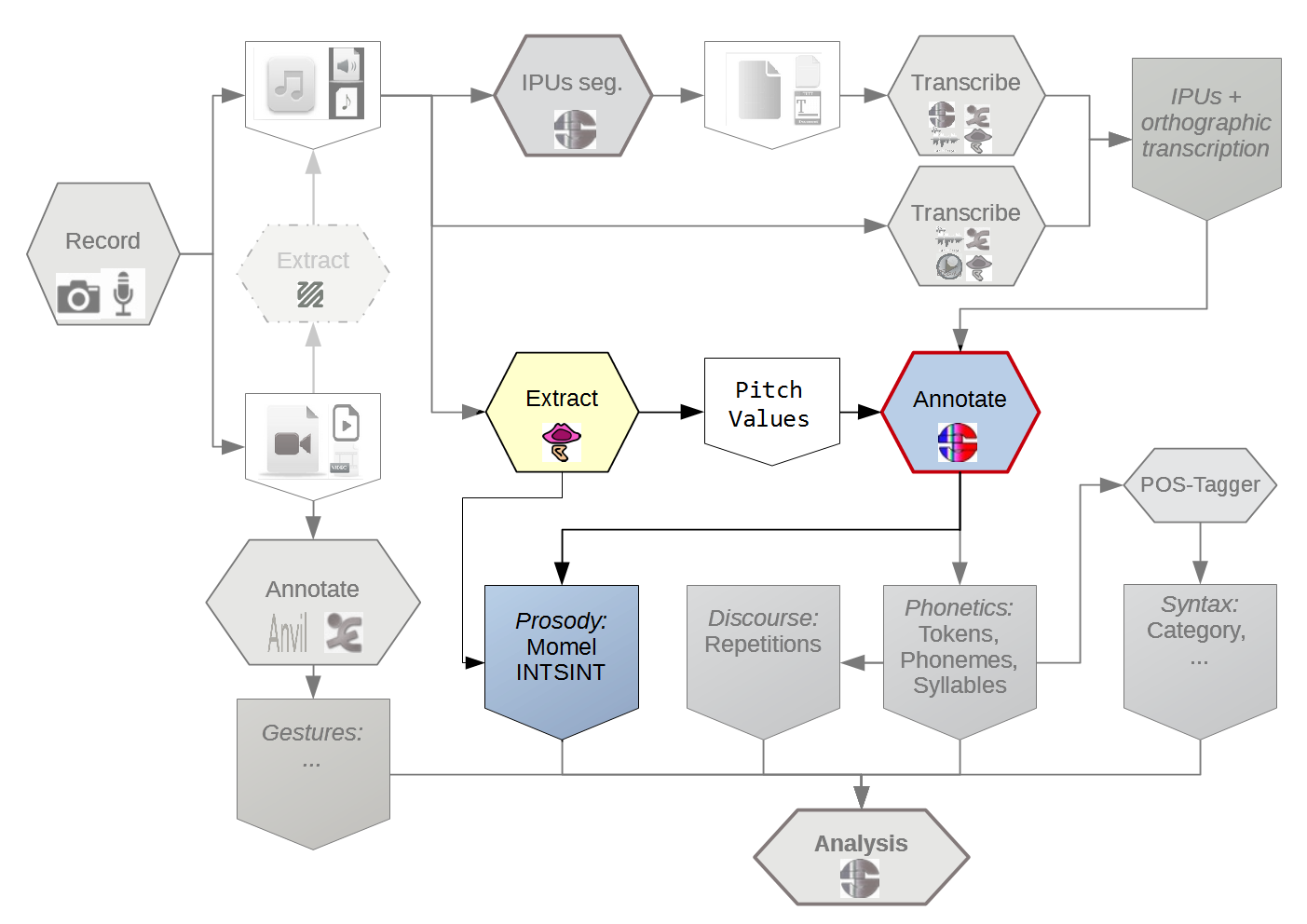
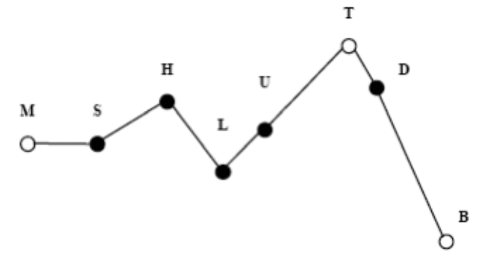
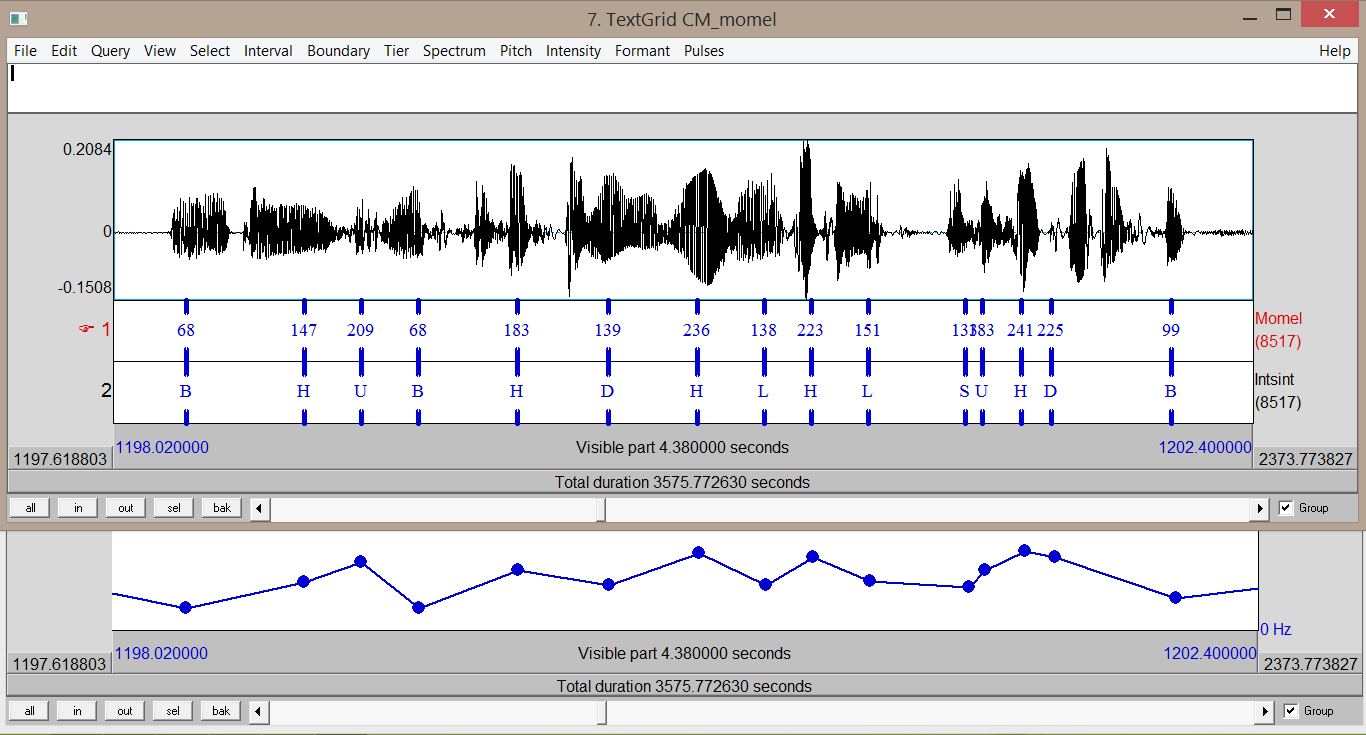
(Hirst and Espesser, 1993)